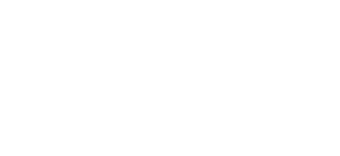
Scarcity of Data Science Unicorns Is Stifling Business Growth
Article originally posted on https://caserta.com
Businesses from every vertical are partnering with data and science consultancies who readily have teams of skilled data science people.
At a symposium on data and analytics at MIT, I heard Ron Bodkin, the technical director of applied Artificial Intelligence at Google, speak about the challenges of Machine Learning. The secret to success, Ron noted, is not only having sufficient computation resources, but also having the right talent, as ML practitioners are hard to find and expensive to hire.
Data science and analytics take a village—and not just any village, but a highly skilled data science village at that. However, with the lack of skilled workers available, many organizations will find themselves in a data science ghost town.

Ron Bodkin delivering Keynote at MIT Symposium
In order to launch a successful data science project, an organization must have sufficient staff consisting of both data scientists and data engineers. Data scientists are the rare mythical unicorns that understand the business while being able to create sophisticated analytical models that are used to build new datasets and derive new insights from data. These data Swiss-army knives have been in short supply since 2012-when the title was coined the sexiest job of the 21st Century.
Data engineers are responsible for much of the work required to support a data science workload. They are highly sought after, scarce, and currently so essential to supporting data science, that some industry experts crowned 2018 as the year of the Data Engineer. Experts in architecting, building and maintaining data-based systems, Data Engineers perform much of the heavy-lifting that supports an organization’s analytical and transactional operations.
“Typically, to run a successful data science project, it takes a ratio of two data engineers for every data scientist,” according to the President and founder of Caserta, Joe Caserta, a strategic data and analytics consultancy. “We’re seeing a lack of engineering talent in the market. Organizations seeking to reduce time-to-value are coming to us not just for a strategic assessment and roadmap for their data science initiatives, but also to implement them with our skilled data engineers.”
Not only is it hard to find data talent, but context is also crucial when it comes to the degree of hiring difficulty. Take the statistical programming language R, for example. Although it is one of the most commonly requested Data Scientist skills, its scarcity among Finance and Risk Analytics Managers makes proficiency in R one of the highest-paying skills for this role. It’s not difficult to understand why the finance industry has already recruited skilled workers from quantitative disciplines to its ranks as Financial Quantitative Analysts.
“The average data science platform take six to 12 months to complete, depending on the complexity and the discovery process,” noted Dovy Paustakys, a senior solutions architect consultant and developer of big data frameworks. “Those six to 12 months can help propel an organization to a value the organization could have only dreamed of, however, afterwards that talent may be squandered.”
Hiring people with the right skills for data science projects is no small feat, but the effort may not even be worth it. Many data science projects take between six to 12 months. It would be untenable to go through the entire hiring process, build a team of venerable data science people, commence a project and move it into production only to not fully utilize them after completion.
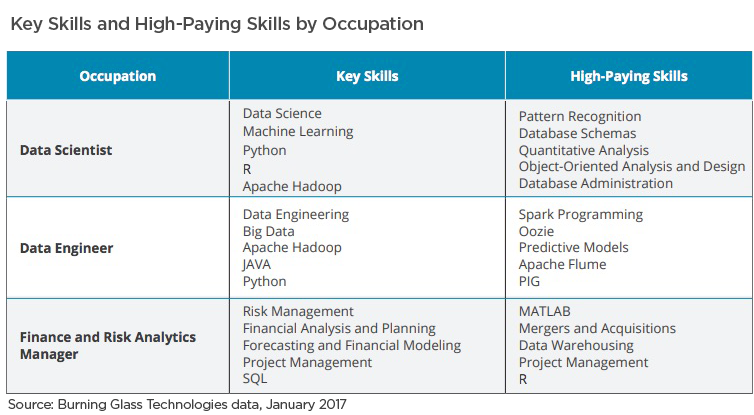
In 2019, demand for data scientists and data engineers will continue to increase and employers across the US will continue struggling to hire workers with these necessary skillsets.Stiff competition in attracting the best hires is hindering the time to value of many organizations’ big data projects. A quick search on Glassdoor reveals 84,548 open data engineer jobs-many exceeding $150k. Searching for “data scientist” returns 23,845 jobs, many also exceeding $150k. Geography is also a critical factor in talent scarcity. Companies far from the tech centers of San Francisco, the Northeast and Texas, will find it more difficult to recruit the talent they need.
“Companies that are not located near tech centers are struggling to bring on the right people for their data science projects,” explains Caserta. “The benefit of working with a data and analytics consultancy, like Caserta, is that our talent is not limited by geography. Our consultants travel to our clients located all over the US and Canada.”
Organizations will either need to figure out methods to attract data talent or find other methods to fulfill the promise of big data. Technology consultancies have readily available teams of skilled data engineers, data scientists and data analysts that can come in, assess a project and then build it. Having worked on many data science projects, teams have the knowledge and experience needed to reduce costs and time to value.
Competition for data science talent will continue to grow. By 2022 the Global Big Data market is expected to reach a staggering $118.52 billion, growing at a CAGR of 26% from 2015 to 2022. Rapid growth in consumer data, advances in information security and improved business efficiencies are some of the agents fueling the market growth. By 2020 there are expected to be 364,000 new DSA job postings in the US.
The best path forward for analytics leaders looking to start a data science project or get one back on track is to partner with a data analytics consultancy. With a large pool of available talent, a consultancy will be able to complete the project on time and budget and advise on how to maintain going forward. This would translate into big-dollar savings, as it wouldn’t be necessary to carry the data science team payroll for years for skills that are no longer affordable or necessary.
“We’re helping many companies with limited resources move their data science projects into production,” notes Caserta. “The majority of firms don’t need to find the expensive scarce talent for short-term projects. Instead, they are better served finding a consultancy like Caserta that will do exactly what they need quickly and efficiently at a lower cost than a firm can do by carrying expensive talent for years.”